Le tadalafil possède une affinité marquée pour la PDE5, mais épargne en grande partie les isoformes PDE1, PDE2 et PDE11, réduisant ainsi le risque d’effets extra-caverneux. L’action se traduit par une augmentation contrôlée de la circulation sanguine locale, indépendante des variations alimentaires. Sa pharmacocinétique repose sur une absorption digestive rapide, un métabolisme hépatique par CYP3A4 et une distribution tissulaire large. La biodisponibilité reste stable, et l’équilibre plasmatique est atteint en quelques jours lors d’administrations répétées. Les interactions cliniquement significatives surviennent avec les inhibiteurs puissants de CYP3A4 tels que le kétoconazole. Dans la littérature pharmacologique, acheter cialis 20 mg est souvent associé à des schémas d’utilisation basés sur la durée prolongée de son action.
Agi-conf.org
ferent amounts of Shannon information, they have one thingin common: Entropy within a chunk is relatively low, en-
We argue that the ability to find meaningful chunks in se-
tropy at chunk boundaries is relatively high. Two kinds of
quential input is a core cognitive ability for artificial generalintelligence, and that the Voting Experts algorithm, which
evidence argue that this signature of chunks is general for
searches for an information theoretic signature of chunks,
the task of chunking sequences and series (see for
provides a general implementation of this ability. In sup-
a similar idea applied to two-dimensional images). First,
port of this claim, we demonstrate that VE successfully finds
the Voting Experts (VE) chunking algorithm and its several
chunks in a wide variety of domains, solving such diverse
variants, all of which detect this signature of chunks, per-
tasks as word segmentation and morphology in multiple lan-
form very well in many domains. Second, when sequences
guages, visually recognizing letters in text, finding episodes
are chunked all possible ways and ranked by a “chunkiness
in sequences of robot actions, and finding boundaries in the
score” that combines within- and between-chunk entropy,
instruction of an AI student. We also discuss further desirable
the highest-ranked chunks are almost always real chunks ac-
attributes of a general chunking algorithm, and show that VE
cording to a gold standard. Here, we focus primarily on the
former kind of evidence, but also provide some early evi-dence of the latter kind.
To succeed, artificial general intelligence requires domain-
independent models and algorithms that describe and imple-
What properties should a general-purpose chunking algo-
ment the fundamental components of cognition. Chunking
rithm have? It must not simply exploit prior knowledge of a
is one of the most general and least understood phenomena
particular domain, but rather must be able to learn to chunk
in human cognition. George Miller described chunking as
novel input. It must operate without supervision in novel do-
“a process of organizing or grouping the input into familiar
mains, and automatically set any parameters it has to appro-
units or chunks.” Other than being “what short term mem-
priate values. For both humans and artificial agents, work-
ory can hold 7 +/- 2 of,” chunks appear to be incommen-
ing memory is finite, and decisions must be made online,
surate in most other respects. Miller himself was perplexed
so the algorithm must be efficient and rely on local informa-
because the information content of chunks is so different. A
tion rather than global optimization. Finally, learning should
telephone number, which may be two or three chunks long,
be rapid, meaning that the algorithm should have relatively
is very different from a chessboard, which may also con-
tain just a few chunks but is vastly more complex. Chunks
VE has these properties. Its name refers to the “experts”
contain other chunks, further obscuring their information
that vote on possible boundary locations. The original ver-
content. The psychological literature describes chunking
sion of VE had two experts: One votes to place bound-
in many experimental situations (mostly having to do with
aries after sequences that have low internal entropy, given
long-term memory) but it says nothing about the intrinsic,
by HI (seq) = −log(p(seq)), the other places votes af-
mathematical properties of chunks. The cognitive science
ter sequences that have high boundary entropy, given by
literature discusses algorithms for forming chunks, each of
which provides a kind of explanation of why some chunks
set of successors to seq. All sequences are evaluated locally,
rather than others are formed, but there are no explanations
within a sliding window, so the algorithm is very efficient.
of what these algorithms, and thus the chunks they find, have
The statistics required to calculate HI and HB are stored
efficiently using an n-gram trie, which is constructed in asingle pass over the corpus. The trie depth is 1 greater than
the size of the sliding window. Importantly, all statistics in
Miller was close to the mark when he compared bits with
the trie are normalized so as to be expressed in standard devi-
chunks. Chunks may be identified by an information the-
ation units. This allows statistics from sequences of different
oretic signature. Although chunks may contain vastly dif-
lengths to be compared to one another.
The sliding window is passed over the corpus and each
Tanaka-Ishii and Jin developed an algorithm
expert votes once per window for the boundary location that
called Phoneme to Morpheme (PtM) to implement ideas
best matches its criteria. VE creates an array of vote counts,
originally developed by Harris in 1955. Harris no-
each element of which represents a location and the number
ticed that if one proceeds incrementally through a sequence
of times an expert voted to segment at that location. The
of phonemes and asks speakers of the language to list all the
result of voting on the string thisisacat could be repre-
letters that could appear next in the sequence (today called
sented as t0h0i1s3i1s4a4c1a0t, where the numbers
the successor count), the points where the number increases
between letters are the total votes cast to split at the corre-
often correspond to morpheme boundaries. Tanaka-Ishii and
Jin correctly recognized that this idea was an early version
With vote totals in place, VE segments at locations that
of boundary entropy, one of the experts in VE. They de-
meet two requirements: First, the number of votes must
signed their PtM algorithm based on boundary entropy in
be locally maximal (this is called the zero crossing rule).
both directions (not merely the forward direction, as in VE),
Second, the number of votes must exceed a threshold.
and PtM was able to achieve scores similar to those of VE
Thus, VE has three parameters: the window size, the vote
on word segmentation in phonetically-encoded English and
threshold, and whether to enforce the zero crossing rule.
Chinese. PtM can be viewed as detecting an information-
For further details of the VE algorithm see Cohen et al.
theoretic signature similar to that of VE, but relying only on
boundary entropy and detecting change-points in the abso-
unsupervised version to the algorithm, which sets its own
lute boundary entropy, rather than local maxima in the stan-
parameters, is described briefly later in the paper.
Also within the morphology domain, Johnson and Mar-
tin’s HubMorph algorithm constructs a trie from a
Some of the best unsupervised sequence-segmentation re-
set of words, and then converts it into a DFA by the pro-
sults in the literature come from the family of algorithms
cess of minimization. Within this DFA, HubMorph searches
derived from VE. At an abstract level, each member of the
for stretched hubs, which are sequences of states in the DFA
family introduces an additional expert that refines or gener-
that have a low branching factor internally, and high branch-
alizes the boundary information produced by the two origi-
ing factor at the edges (shown in Figure This is a nearly
nal VE experts to improve segmentation quality. Extensions
identical chunk signature to that of VE, only with succes-
to VE include Markov Experts Hierarchical Vot-
sor/predecessor count approximating boundary entropy. The
ing Experts - 3 Experts (HVE-3E) and Bootstrap
generality of this idea was not lost on Johnson and Martin,
either: Speaking with respect to the morphology problem,
The first extension to VE introduced a “Markov Expert,”
Johnson and Martin close by saying “We believe that hub-
which treats the segmentation produced by the original ex-
automata will be the basis of a general solution for Indo-
perts as a data corpus and analyzes suffix/prefix distributions
European languages as well as for Inuktitut.”
within it. Boundary insertion is then modeled as a Markovprocess based on these gathered statistics. HVE-3E is sim-pler: The third expert votes whenever it recognizes an entirechunk found by VE on the first iteration.
The new expert in BVE is called the knowledge expert.
The knowledge expert has access to a trie (called the knowl-edge trie) that contains boundaries previously found by thealgorithm, and votes to place boundaries at points in thesequence that are likely to be boundaries given this in-
Figure 1: The DFA signature of a hub (top) and stretched
formation. In an unsupervised setting, BVE generates its
hub in the HubMorph algorithm. Figure from Johnson and
own supervision by applying the highest possible confidence
threshold to the output of VE, thus choosing a small, high-precision set of boundaries. After this first segmentation,BVE repeatedly re-segments the corpus, each time con-structing the knowledge trie from the output of the previous
iteration, and relaxing the confidence threshold. In this way,BVE starts from a small, high-precision set of boundaries
To demonstrate the domain-independent chunking ability
and grows it into a larger set with higher recall.
of VE, we now survey a variety of domains to which VEhas been successfully. Some of these results appear in the
literature, others are new and help to explain previous re-
While Cohen and Adams were the first to formulate
sults. Unless otherwise noted, segmentation quality is mea-
the information-theoretic signature of chunks that drives VE,
sured by the boundary F-measure: F = (2 × Precision ×
similar ideas abound. In particular, simpler versions of the
Recall)/(Precision+Recall), where precision is the percent-
chunk signature have existed within the morphology domain
age of the induced boundaries that are correct, and recall is
the percentage of the correct boundaries that were induced.
not been examined previously. Morph segmentation is a
VE and its variants have been tested most extensively in lin-
harder task to evaluate than word segmentation, because
guistic domains. Language arguably contains many levels
intra-word morph boundaries are typically not indicated
of chunks, with the most natural being the word. The word
when writing or speaking. We constructed a gold standard
segmentation task also benefits from being easily explained,
corpus of Latin text segmented into morphs with the mor-
well-studied, and having a large amount of gold-standard
data available. Indeed, any text can be turned into a cor-pus for evaluating word segmentation algorithms simply by
have been reported in nearly every VE-related paper, and so
is the most general comparison that can be drawn. This cor-pus is the first 50,000 characters of George Orwell’s 1984. Table shows the aggregated results for VE and its deriva-
Table 2: Morph-finding results by algorithm. All Points is a
baseline that places a boundary at every possible location.
From the table above (Table it is clear that VE in
its standard form has some difficulty finding the correct
morphs. Still, its performance is comparable to PtM on
this task, as expected due to the similarity in the two al-
gorithms. PtM’s advantage probably is due to its bidirec-
tionality: VE only actually examines the boundary entropy
at the right (forward) boundary. VE was modified with theaddition of an expert that places its votes before sequencesthat have high boundary entropy in the backward direction.
Table 1: Results for VE and VE variants for word segmen-
This bidirectional version of VE, referred to as BidiVE, is
a more faithful implementation of the idea that chunks aresequences with low internal entropy and high boundary en-
Similar results can be obtained for different underlying
tropy. BidiVE performed better than VE at finding morphs
languages, as well as different writing systems. Hewlett and
Cohen showed similar scores for VE in Latin (F=0.772) and
For reference, when the task is to find word boundaries,
German (F=0.794) texts, and also presented VE results for
the F-score for VE is approximately 0.77 on this same cor-
word segmentation in orthographic Chinese (“Chinese char-
pus. The reason for this is somewhat subtle: Because VE
acters”). VE achieved an F-score of 0.865 on a 100,000
only looks at entropy in the forward direction, it will only
word section of the Chinese Gigaword Corpus.
consider the entropy after a morph, not before it. Consider
The higher score for Chinese than for the other languages
a word like senat.us: The entropy of the next character
has a simple explanation: Chinese characters correspond
following senat is actually fairly low, despite the fact that
roughly to syllable-sized units, while the letters in the Latin
it is a complete morph. This is because the set of unique
alphabet correspond to individual phonemes. By grouping
endings that can appear with a given stem like senat is
letters/phonemes into small chunks, the number of correct
actually fairly small, usually less than ten. Furthermore, in
boundary locations remains constant, but the number of po-
any particular text a word will only appear in certain syntac-
tential boundary locations is reduced. The means that even a
tic relationships, meaning the set of endings it actually takes
baseline like All Locations, which places a boundary at ev-
will be smaller still. However, the entropy of the character
ery possible location, will perform better when segmenting
preceding us is very high, because us appears with a large
a sequence of syllables than a sequence of letters.
number of stems. This fact goes unnoticed by VE.
VE has also been tested on phonetically-encoded English,
in two areas: First, transcripts of of child-directed speech
dence relevant to an important debate within the child lan-
from the CHILDES database Second, on a phone-
guage learning literature: How do children learn to seg-
mic encoding of 1984 produced with the CMU pronounc-
ment the speech stream into words? Famously, Saffran et
ing dictionary. On the CHILDES data, VE was able to find
al. showed that 8-month-old infants were able to
word boundaries as well or better (F=0.860) than several
distinguish correctly and incorrectly segmented words, even
other algorithms, even though the other algorithms require
when those words were nonsense words heard only as part
their inputs to be sequences of utterances from which in-
of a continuous speech stream. This result challenges mod-
formation about utterance beginnings and endings can be
els of word segmentation, such as Brent’s MBDP-1
gathered VE achieved an F-score of 0.807 on the
which cannot operate without some boundary information.
Saffran et al. proposed that children might segment continu-
While the word segmentation ability of VE
ous sequences at points of low transitional probability (TP),
has been studied extensively, its ability to find morphs has
the simplest method which would successfully segment their
robot wandered around a large playpen for 20-30 minutes
However, TP alone performs very poorly on natural lan-
looking for interesting objects, which it would orbit for a
guage, a fact which has not escaped opponents of the view
few minutes before moving on. At one level of abstraction,
that word segmentation is driven by distributional properties
the robot engaged in four types of behaviors: wandering,
rather than innate knowledge about language. Linguistic na-
avoiding, orbiting and approaching. Each behavior was im-
tivists such as Gambell and Yang argue that this
plemented by sequences of actions initiated by controllers
failure of TP to scale up to natural language suggests that
such as move-forward and center-camera-on-object. The
the statistical segmentation ability that children possess is
challenge for Voting Experts was to find the boundaries of
limited and likely orthogonal to a more powerful segmenta-
the four behaviors given only information about which con-
tion ability driven by innate linguistic knowledge. Gambell
and Yang demonstrate that an algorithm based on linguis-
This experiment told us that the encoding of a sequence
tic constraints (specifically, constraints on the pattern of syl-
matters: When the coding produced shorter behaviors (aver-
lable stress in a word) significantly outperforms TP when
age length of 7.95 time steps), VE’s performance was com-
segmenting a corpus of phonetically-encoded child-directed
parable to that in earlier experiments (F=0.778), but when
speech. In fact, VE can further outperform Gambell and
the coding produced longer behaviors, performance is very
Yang’s method (F=0.953 vs. F=0.946) even though VE has
much worse (F=0.183). This is because very long episodes
no prior knowledge of linguistic constraints, suggesting that
are unique, so most locations in very long episodes have zero
adding innate knowledge may not be as useful as simply in-
boundary entropy and frequency equal to one. And when the
creasing the power of the chunking method.
window size is very much smaller than the episode length,
Algorithms like VE and PtM provide a counter-argument
then there will be a strong bias to cut the sequence inappro-
to the nativist position, by fully explaining the results that
Saffran et al. observed, and also performing very well at seg-menting natural language. When represented symbolically
as a sequence of phonemes, VE perfectly segments the sim-
The goal of the DARPA’s Bootstrapped Learning (BL)
ple artificial language generated by Saffran et al.
project is to develop an “electronic student” that can be in-
while also performing well in the segmentation of child-
structed by human teachers, in a natural manner, to perform
directed speech. Miller et al. reinforce this case
complex tasks. Currently, interaction with the electronic stu-
by replicating the experimental setup of Saffran et al., but
dent is not very different from high-level programming. Our
feeding the speech input to VE instead of a child. The audio
goal is to replace many of the formal cues or “signposts” that
signal had to be discretized before VE could segment it, but
enable the electronic student to follow the teacher, making
VE was able to achieve an accuracy of 0.824.
the interaction between them more natural. VE can largelyreplace one of these cues: the need to inform the student
whenever the teacher’s instruction method changes.
Miller and Stoytchev applied VE in a hierarchical
In BL, teachers communicate with the student in a lan-
fashion to perform a visual task similar to optical charac-
guage called Interlingua language (IL). Some IL messages
ter recognition (OCR). The input was an image containing
serve only to notify the student that a “Lesson Epoch” (LE)
words written in a particular font. VE was to first segment
this image into short sequences corresponding to letters, and
Several curricula have been developed for BL. VE finds
then chunk the short sequences into longer sequences cor-
LE boundaries with high accuracy in all of them – and can
responding to words. The image was represented as a se-
be trained on one and tested on another to good effect. To
quence of columns of pixels, where each pixel was either
illustrate, we will present results for the Unmanned Aerial
black or white. Each of these pixel columns can be repre-
Vehicle (UAV) domain. To study the detection of LE bound-
sented by a symbol denoting the particular pattern of black
aries, a training corpus was generated from version 2.4.01
and white pixels within it, thus creating a sequence of sym-
of the UAV curriculum by removing all of the messages that
bols to serve as input to VE. Depending on the font used, VE
indicate boundaries between LEs. This training corpus con-
scored between F=0.751 and F=0.972 on segmenting this
tains a total of 742 LEs. A separate corpus consisting of 194
LEs served as a test corpus. As the teacher should never have
After finding letters, VE had to chunk these letters to-
to provide LE boundaries, the problem is treated as unsuper-
gether into words, which is essentially the same as the well-
vised and both the training and test corpora are stripped of
studied word segmentation problem except with some noise
added to the identification of each character. VE was still
Each individual message in the corpus is a recursive struc-
able to perform the task, with scores ranging from F=0.551
ture of IL objects that together express a variety of relations
to F=0.754 for the three fonts. With perfect letter identifica-
about the concepts being taught and the state of teaching.
LEs are defined more by the structure of the message se-quence than the full content of each message. Thus, we rep-
resent each message as a single symbol, formed by concate-
Cohen et al. tested VE on data generated by a
nating the IL type of the two highest composite IL objects
mobile robot, a Pioneer 2 equipped with sonar and a pan-
(generally equivalent to the message’s type and subtype).
tilt-zoom camera running a subsumption architecture. The
The sequence of structured messages is thus translated into
Though the success of VE in a given domain provides in-direct evidence that the chunk signature successfully iden-
tifies chunks in that domain, we can evaluate the validity
of the chunk signature much more directly. To evaluate the
ability of the chunk signature to select the true segmentation
from among all possible segmentations of a given sequence,we developed a “chunkiness” score that can be assigned to
Table 3: BVE Results on UAV Domain trained on different
each possible segmentation, thus ranking all possible seg-
subsets of the training corpus. “Size” is percentage of the
mentations by the quality of the chunks they contain. The
chunkiness score rewards frequent sequences that have highentropy at both boundaries (Equation just as in VE. Thescore for a complete segmentation is simply the average ofthe chunkiness of each segment. If the chunk signature is
a sequence of symbols, and it is this symbol sequence that
correct, the true segmentation should have a very high score,
and so will appear close to the top of this ranking. Unfor-
BVE is allowed to process the training corpus repeatedly
tunately, due to the exponential increase in the number of
to gather statistics and segment it, but the segmentation of
segmentations (a sequence of length n has 2n−1 segmenta-
the test corpus must be done in one pass, to model more
tions), this methodology can only be reasonably applied to
closely the constraints of a real teacher-student interaction.
short sequences. However, it can be applied to many such
If allowed to operate on the full UAV corpus, BVE finds LE
short sequences to better gain a better estimate of the de-
boundaries handily, achieving an F-score of 0.907. How-
gree to which optimizing chunkiness optimizes segmenta-
ever, this domain is non-trivial: VE achieves an F-score of
0.753, only slightly lower than its score for word segmenta-tion in English text. As a baseline comparison, segmenting
the corpus at every location results in an F-score of 0.315,
which indicates that LE boundaries are roughly as frequent
For each 5-word sequence (usually between 18 and 27
as word boundaries in English, and thus that high perfor-
characters long) in the Bloom73 corpus from CHILDES, we
mance is not guaranteed simply by the frequency of bound-
generated all possible segmentations and ranked them all by
chunkiness. On average, the true segmentation was in the
Results from segmenting a test corpus (not drawn from
98.7th percentile. All probabilities needed for computing
the training corpus) consisting of 194 lesson epochs are
the chunkiness score were estimated from a training corpus,
shown in Table “Training Size” refers to the percentage
the Brown73 corpus (also from CHILDES). Preliminarily, it
of the training corpus processed by BVE before segmenting
appears that syntax is the primary reason that the true seg-
the test corpus. From these results, it is evident that BVE
mentation is not higher in the ranking: When the word-order
can perform very well on a new corpus when the training
in the training corpus is scrambled, the true segmentation is
corpus is sufficiently large. However, with a small training
in the 99.6th percentile. Still, based on these early results we
corpus BVE does not encounter certain boundary situations,
can say that, in at least one domain, optimizing chunkiness
and thus fails to recognize them during the test, resulting in
very nearly optimizes segmentation quality.
Automatic Setting of ParametersVE has tunable parameters, and Hewlett and Cohen
showed that these parameters can greatly affect perfor-mance. However, they also demonstrated how these pa-
So far, we have discussed in detail one kind of evidence for
rameters can be tuned without supervision. Minimum De-
the general applicability of VE, namely that VE success-
scription Length (MDL) provides an unsupervised way to
fully performs unsupervised segmentation in a wide variety
set these parameters indirectly by selecting among the seg-
of domains. In order for VE to be successful in a given do-
mentations each combination of parameters generates. The
main, chunks must exist in that domain that adhere to the
Description Length for a given hypothesis and data set refers
VE’s signature of chunks, and VE must correctly identify
to the number of bits needed to represent both the hypoth-
these chunks. Thus, the success of VE in each of these
esis and the data given that hypothesis. The Minimum De-
domains is evidence for the presence of chunks that ad-
scription Length, then, simply refers to the principle of se-
here to the signature in each domain. Also, VE’s chunk
lecting the hypothesis that minimizes description length. In
signature is similar to (or a direct generalization of) sev-
this context, the data is a corpus (sequence of symbols), and
eral other independently-developed signatures, such as PtM,
the hypotheses are proposed segmentations of that corpus,
HubMorph, and the work of Kadir and Brady The
each corresponding to a different combination of parameter
independent formulation of similar signatures by researchers
settings. Thus, we choose the vector of parameter settings
working in different domains suggests that a common prin-
that generates the hypothesized segmentation which has the
ciple is at work across those domains.
Strictly speaking, VE can only operate over sequences of
[Bre99] Michael R Brent. An Efficient, Probabilistically
Sound Algorithm for Segmentation and Word Discovery.
Miller et al.’s applications of VE to the visual and auditory
Machine Learning, pages 71–105, 1999.
domains, many sequences of multivariate or continuous-
[CA01] P Cohen and N Adams. An algorithm for segment-
valued data can be transformed into a symbolic representa-
ing categorical time series into meaningful episodes. Lec-
tion for VE. Also, the SAX algorithm provides
ture notes in computer science, 2001.
a general way to convert a stream of continuous data into a
[CAH07] Paul Cohen, Niall Adams, and Brent Heeringa.
Voting Experts: An Unsupervised Algorithm for Segment-ing Sequences.
[CM05] Jimming Cheng and Michael Mitzenmacher. The
While the ability of VE to operate in a fully unsupervised
Markov Expert for Finding Episodes in Time Series. In
setting is certainly a strength, the fact that VE contains no
Proceedings of the Data Compression Conference (DCC
natural mechanism for incorporating supervision may be
seen as a limitation: If some likely examples of ground truthboundaries are available, the algorithm ought to be able to
[GY05] Timothy Gambell and Charles Yang. Word Seg-
take advantage of this information. While VE itself cannot
mentation: Quick but not Dirty. 2005.
benefit from true boundary knowledge, one of its extensions,
BVE, does so handily. BVE’s knowledge trie can store pre-
viously discovered boundaries (whether provided to or in-
[HC09] Daniel Hewlett and Paul Cohen. Bootstrap Vot-
ferred by the algorithm), and the knowledge expert votes for
ing Experts. In Proceedings of the Twenty-first Interna-
boundary locations that match this prior knowledge. The
tional Joint Conference on Artificial Intelligence (IJCAI-
Markov Experts version is able to benefit from supervision
in a similar way, and, if entire correct chunks are known,
[JM03] Howard Johnson and Joel Martin. Unsupervised
learning of morphology for English and Inuktitut. Proceed-ings of the 2003 North American Chapter of the Associ-
ation for Computational Linguistics on Human LanguageTechnology (NAACL-HLT 03), pages 43–45, 2003.
VE does not represent explicitly a “lexicon” of chunks thatit has discovered. VE produces chunks when applied to a
[KB01] Timor Kadir and Michael Brady. Saliency, Scale
sequence, but its internal data structures do not represent the
and Image Description. International Journal of Computer
chunks it has discovered explicitly. By contrast, BVE stores
boundary information in the knowledge trie and refines it
[LKWL07] Jessica Lin, Eamonn Keogh, Li Wei, and Ste-
over time. Simply by storing the beginnings and endings
fano Lonardi. Experiencing SAX: a novel symbolic rep-
of segments, the knowledge trie comes to store sequences
resentation of time series. Data Mining and Knowledge
like #cat#, where # represents a word boundary. The set
Discovery, 15:107–144, April 2007.
of such bounded sequences constitutes a simple, but accu-
[MS85] Brian McWhinney and Cynthia E. Snow. The child
rate, emergent lexicon. After segmenting a corpus of child-
language data exchange system (CHILDES). Journal of
directed speech, the ten most frequent words of this lexicon
are you, the, that, what, is, it, this, what’s, to, and look. Of
[MS08] Matthew Miller and Alexander Stoytchev. Hierar-
the 100 most frequent words, 93 are correct. The 7 errors
chical Voting Experts: An Unsupervised Algorithm for Hi-
include splitting off morphemes such as ing, and merging
erarchical Sequence Segmentation. In Proceedings of the
frequently co-occurring word pairs such as do you.
7th IEEE International Conference on Development andLearning (ICDL 2008), pages 186–191, 2008.
[MWS09] Matthew Miller, Peter Wong, and Alexander
Stoytchev. Unsupervised Segmentation of Audio Speech
Chunking is one of the domain-independent cognitive abili-
Using the Voting Experts Algorithm. Proceedings of the
ties that is required for general intelligence, and VE provides
2nd Conference on Artificial General Intelligence (AGI
a powerful and general implementation of this ability. We
have demonstrated that VE and related algorithms performwell at finding chunks in a wide variety of domains, and pro-
[SAN96] Jenny R Saffran, Richard N Aslin, and Elissa L
vided preliminary evidence that chunks found by maximiz-
Newport. Statistical Learning by 8-Month-Old Infants. Sci-
ing chunkiness are almost always real chunks. This suggests
that the information theoretic chunk signature that drives VE
[TIJ06] Kumiko Tanaka-Ishii and Zhihui Jin.
is not specific to any one domain or small set of domains.
Phoneme to Morpheme: Another Verification Using a Cor-
We have discussed how extensions to VE enable it to operate
pus. In Proceedings of the 21st International Conference
over nearly any sequential domain, incorporate supervision
on Computer Processing of Oriental Languages (ICCPOL
when present, and tune its own parameters to fit the domain.
2006), volume 4285, pages 234–244, 2006.
1 Now the Holy Spirit tells us clearly that in the last times some will turn away from the true faith; they will follow deceptive spirits and teachings that come from demons. 2 These people are hypocrites and liars, and their consciences are dead. 3 They will say it is wrong to be married and wrong to eat certain foods. But God created those foods to be eaten with thanks by faithful people wh
Doctors Memorial Hospital - Radiology Department Consent for IV Iodine Administration Name: _________________________________________________Height: ____________ Weight: ______________Current Medicines_________________________________________________________________________________________________________________________________________________________________________________________________
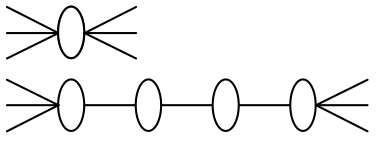 The sliding window is passed over the corpus and each
Tanaka-Ishii and Jin developed an algorithm
expert votes once per window for the boundary location that
called Phoneme to Morpheme (PtM) to implement ideas
best matches its criteria. VE creates an array of vote counts,
originally developed by Harris in 1955. Harris no-
each element of which represents a location and the number
ticed that if one proceeds incrementally through a sequence
of times an expert voted to segment at that location. The
of phonemes and asks speakers of the language to list all the
result of voting on the string thisisacat could be repre-
letters that could appear next in the sequence (today called
sented as t0h0i1s3i1s4a4c1a0t, where the numbers
The sliding window is passed over the corpus and each
Tanaka-Ishii and Jin developed an algorithm
expert votes once per window for the boundary location that
called Phoneme to Morpheme (PtM) to implement ideas
best matches its criteria. VE creates an array of vote counts,
originally developed by Harris in 1955. Harris no-
each element of which represents a location and the number
ticed that if one proceeds incrementally through a sequence
of times an expert voted to segment at that location. The
of phonemes and asks speakers of the language to list all the
result of voting on the string thisisacat could be repre-
letters that could appear next in the sequence (today called
sented as t0h0i1s3i1s4a4c1a0t, where the numbers